Note: This blog post is co-authored by Daniel Shechter, CEO and co-founder of Miggo Security, and Jonathan Price, Director of Security Operations at Grafana Labs.
Modern runtime security is critical to understand complex systems and detect and protect against attacks, especially in rapidly evolving cloud native architectures. For many security teams, however, achieving deep visibility into runtime risks remains a moving target.
To address this challenge, Grafana Labs and Miggo Security, a leader in AI-driven runtime security and application detection and response (ADR), have partnered on a joint solution to deliver evidence-based runtime security without the typical runtime costs. The solution builds directly on existing production telemetry in Grafana Cloud to help organizations determine what is truly exposed, what actually executes in production, and which vulnerabilities represent real, exploitable risk. Most importantly, it does this without duplicating instrumentation or introducing operational overhead.
In this blog, we’ll explore why securing modern cloud native workloads has traditionally been a challenge, the limitations of traditional runtime approaches, and how building security directly on top of Grafana Cloud represents a major step forward for CISOs, application owners, and platform engineering teams.
The Problem: Securing Cloud Native Applications
The shift toward microservices has fundamentally changed the attack surface. As development velocity increases, it’s more difficult than ever to understand how your systems really function, how they might be attacked, or how they’re already under attack today.
Traditional security methods like static application security testing (SAST) and software composition analysis (SCA) rely on scanning our code and dependencies at build time. While this can surface potential issues in our own code and every published vulnerability possibly present in our dependencies, the true positive rate is painfully low: only 2% of discovered dependency vulnerabilities are actually exploitable. The other 98% exists in code the running system never calls. Tools like dynamic or interactive application security testing (DAST/IAST) try to mitigate this problem, but trade false positive rates for intensive setup and maintenance.
While widely utilized, such approaches are no longer sufficient. Teams are currently overloaded with vulnerabilities that turn out to be irrelevant, while actual critical vulnerabilities go unnoticed. The common practice of pushing this noise onto developers or ops teams to manage erodes trust: when 98% of the issues we ship to them have no real risk, developers are right not to trust us.
The Promise and Pain of Runtime Security
The solution the industry is gravitating towards is runtime security. If we deploy standard sensors on our running workloads, we can know what services are actually running in production, what they connect to, and what functions they actually call. Not only can we see how connected and sensitive a service is to prioritize it, we can see if a vulnerability is reachable and if the vulnerable section of code is actually called. This information about reachability allows us to immediately focus on the 2% of vulnerabilities that actually matter. We can show owning software teams exactly why a vulnerability matters, building trust rather than hurting it.
This has great promise, but also comes with challenges. There are a few key reasons why achieving visibility into runtime risk is particularly difficult.
Challenge 1: The Deployment Tax
Runtime security has a cost.
Runtime application self-protection (RASP) of the 2010s proved that deep runtime instrumentation could unlock real application visibility, but at a steep cost: performance drag, vendor lock-in, and fragile upgrades.
eBPF emerged over the 2020s as an answer, sidestepping runtime dependencies by hooking directly into the kernel. This dramatically improves ease of deployment over RASP, and has led to hundreds of vendors leveraging eBPF sensors to collect runtime signals to power a range of security products. This innovation, again, comes with a cost: each eBPF sensor can add 1-3% of compute overhead. There is no standardization for this collection in the security industry, so security teams can end up paying different vendors to collect and store the same data to power their different products, and further pay compute overhead over 10% on their running workloads.
This further strains relationships and erodes trust: platform teams do not want heavy security sensors slowing down their production environments — or worse, breaking them.
Challenge 2: Runtime Context
Most runtime security solutions operate at the level of a single process or container, blind to broader context. Cutting through the noise requires understanding the actual threat model: whether an attacker can realistically exploit a vulnerability, whether the vulnerable service is even reachable, and the potential blast radius.
The result is an overwhelmed security team, fielding both static and runtime findings with no principled way of connecting and prioritizing. Fixing everything is impossible, and prioritizing incorrectly means expending energy without reducing risk.
Challenge 3: The Affected programRoutine Problem
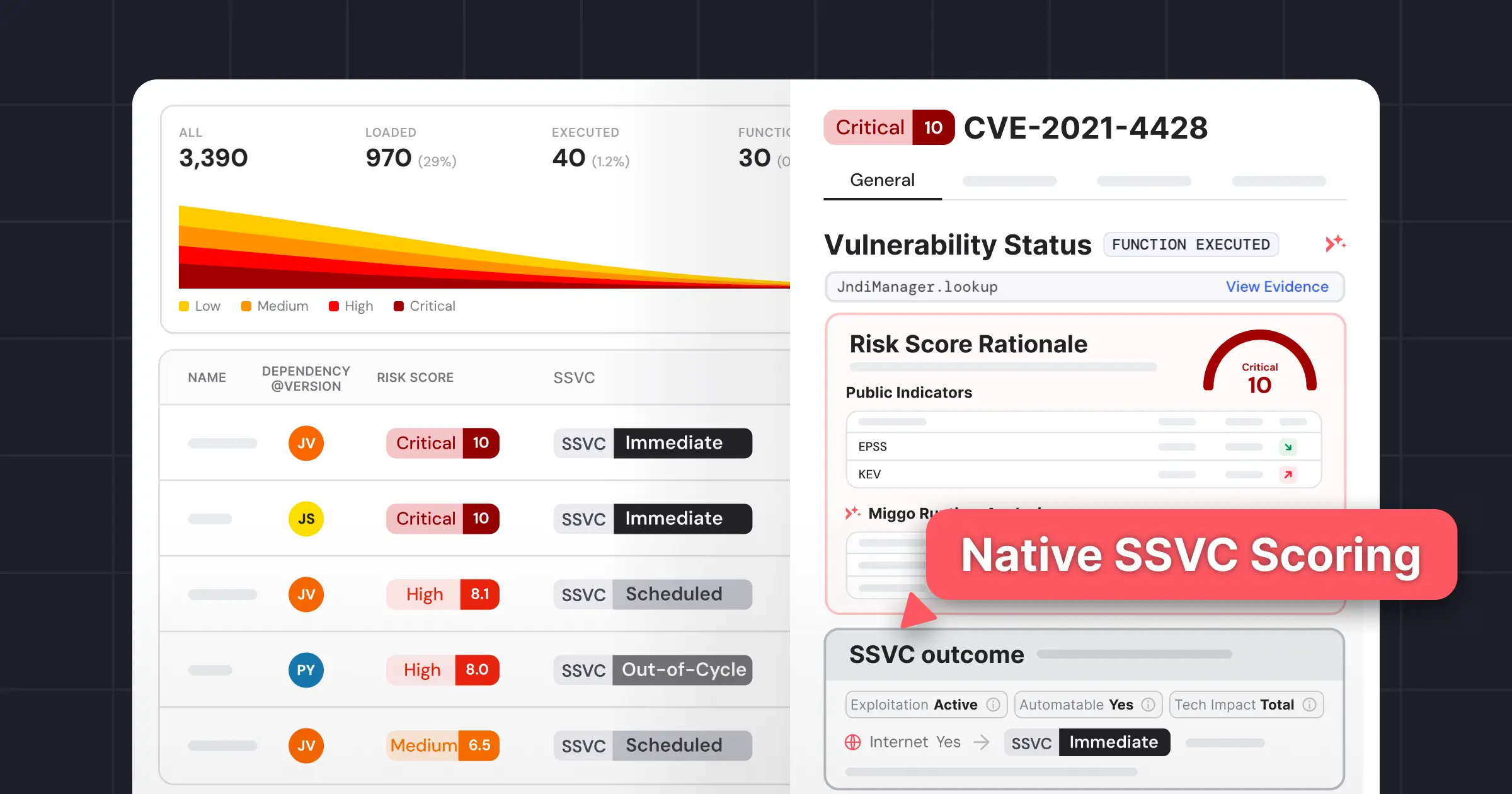
In order to understand if you’re running a vulnerable piece of code from a dependency, we need to know the actual pieces of code we’re running. The way this is intended to work is that dependency maintainers include a programRoutine (a specific method or function) in the list of affected systems in a CVE record. Then, we can look for invocations of that function on our running services, and know if the vulnerability is reachable.
This would be great, if dependency maintainers consistently included these definitions in their CVE records. Unfortunately, they don’t; less than 10% of CVE records contain an affected programRoutine. And actually, Grafana Labs is one of those maintainers not consistently including these in our CVEs records. To be clear, this is partially intentional: calling out the affected programRoutine would make it easier to write an exploit. However, this still limits the full promise of runtime visibility.
Enter Miggo and Grafana Cloud: Execution-backed Security with Zero Added Complexity
All of these challenges are solvable. While every runtime security vendor has their own bespoke sensor, they do not need to. And this doesn’t require defining new standards; the standards already exist. Runtime security depends on the same core system signals, such as metrics, logs, traces, and profiles, that already exist within most organizations’ observability stacks.
Grafana Labs and Miggo are excited to announce our partnership leveraging these synergies. Grafana Cloud customers already collect the traces and profiles that are at the core of runtime security. Instead of adding new sensors and re-collecting the same signals, Miggo builds directly on Grafana Cloud Traces, the fully managed distributed tracing system powered by Tempo, and Grafana Cloud Profiles, the hosted continuous profiling tool powered by Pyroscope. This solves the deployment tax challenge, as this model requires deploying and maintaining zero additional sensors for security teams.
With Miggo’s advanced vulnerability and system analysis, we also solve the runtime context and affected programRoutine challenges. Miggo’s vulnerability research team finds the affected functions not disclosed in CVEs, giving users true visibility into what vulnerabilities are actively exploitable in their systems. Miggo further analyzes the telemetry data to give security teams a complete picture of their system state, and integrates with security systems to drive mitigation.
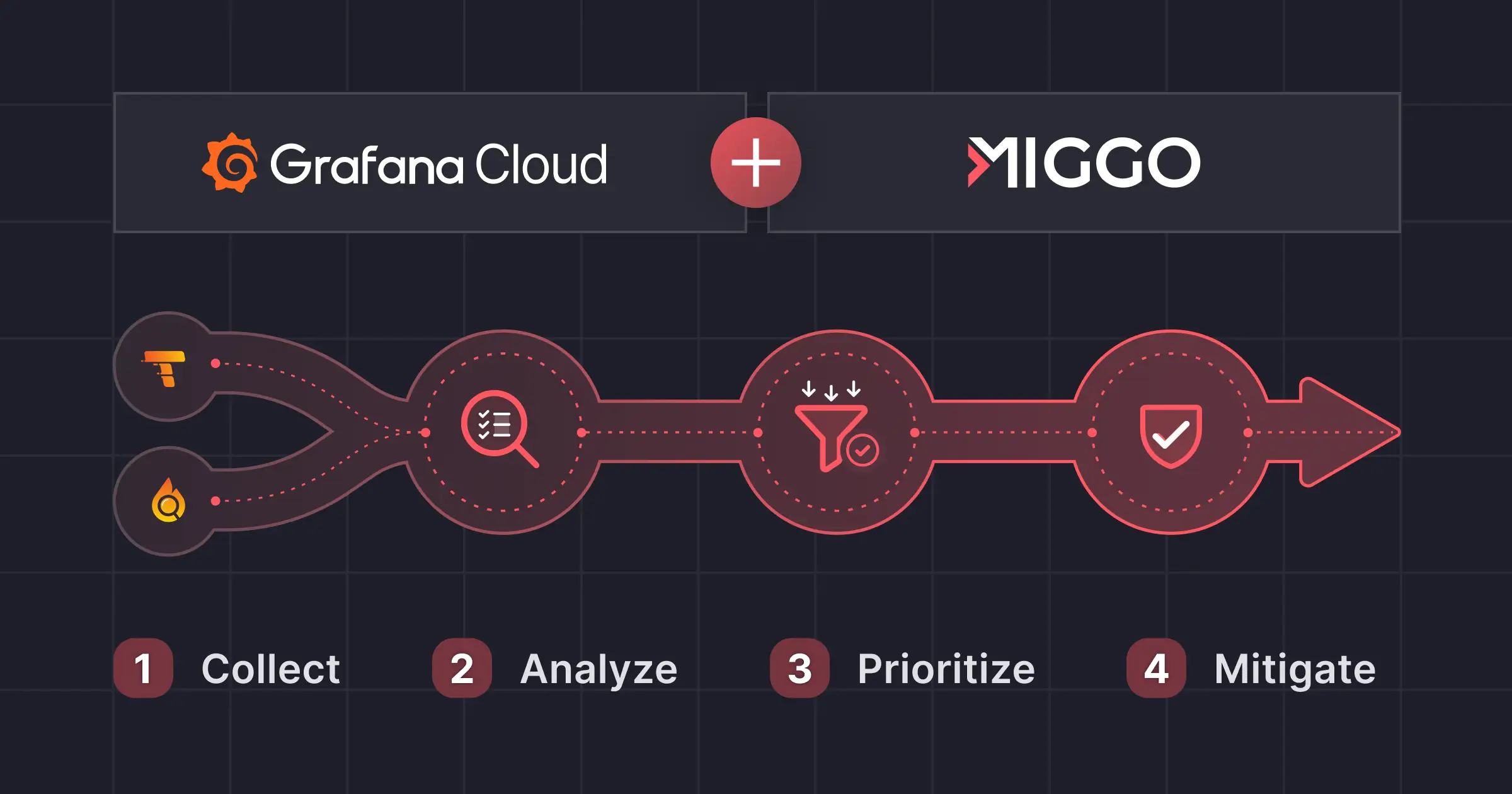
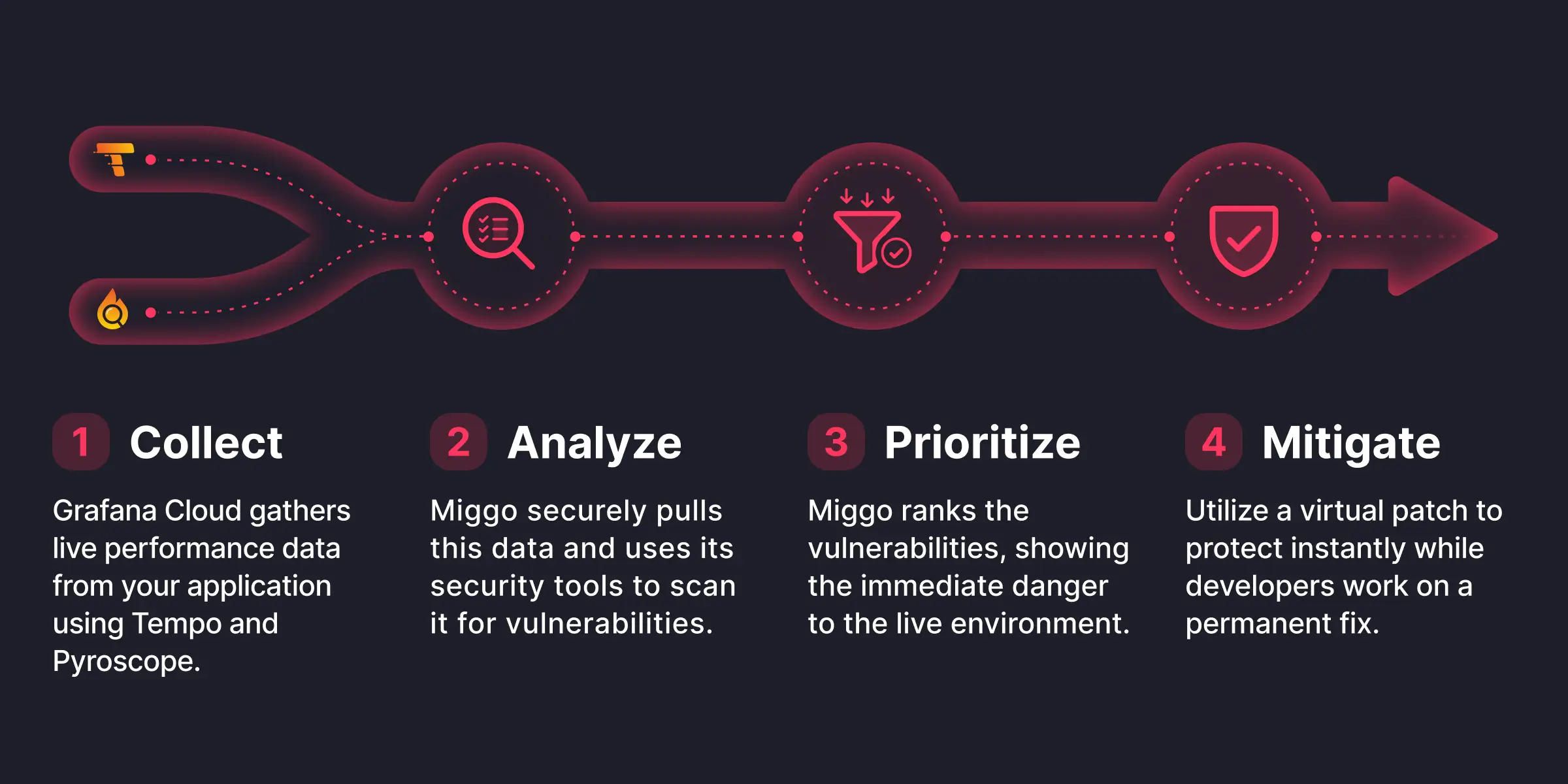
In a nutshell, the process works like this:
Step 1: Collect (Grafana Cloud)
- Developers collect telemetry data on their systems leveraging the same tools they already use, including direct instrumentation, Alloy, Beyla, or any other OTel collector
- Telemetry data is ingested into Grafana Cloud Traces (request flows, service interactions, endpoints) and Grafana Cloud Profiles (what code paths actually ran)
Step 2: Analyze (Miggo)
- Ingest via Grafana Cloud APIs, correlate with vulnerability intel
- Determine reachability, exposure, blast radius, and exploitability indicators
- Build dynamic runtime application graph/inventory
Step 3: Prioritize
- Execution-backed prioritization
- Focus remediation on what materially impacts risk
Step 4: Mitigate
- Miggo WAF Copilot generates vulnerability-specific protections (virtual patches) based on observed traffic patterns
Use Cases
Below, we walk through three examples of how this powerful combination solves critical security challenges.
1. Establishing Runtime Truth
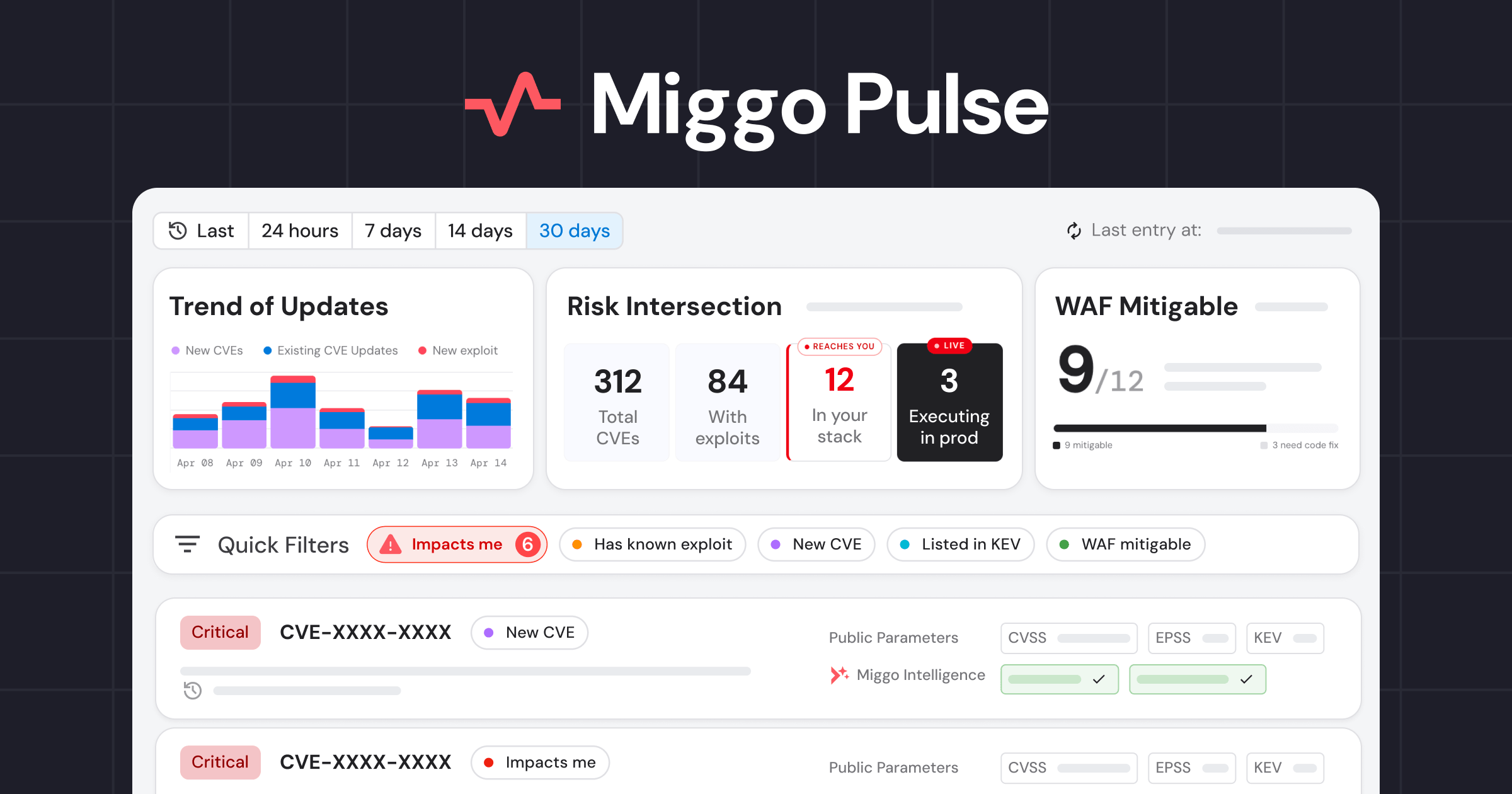
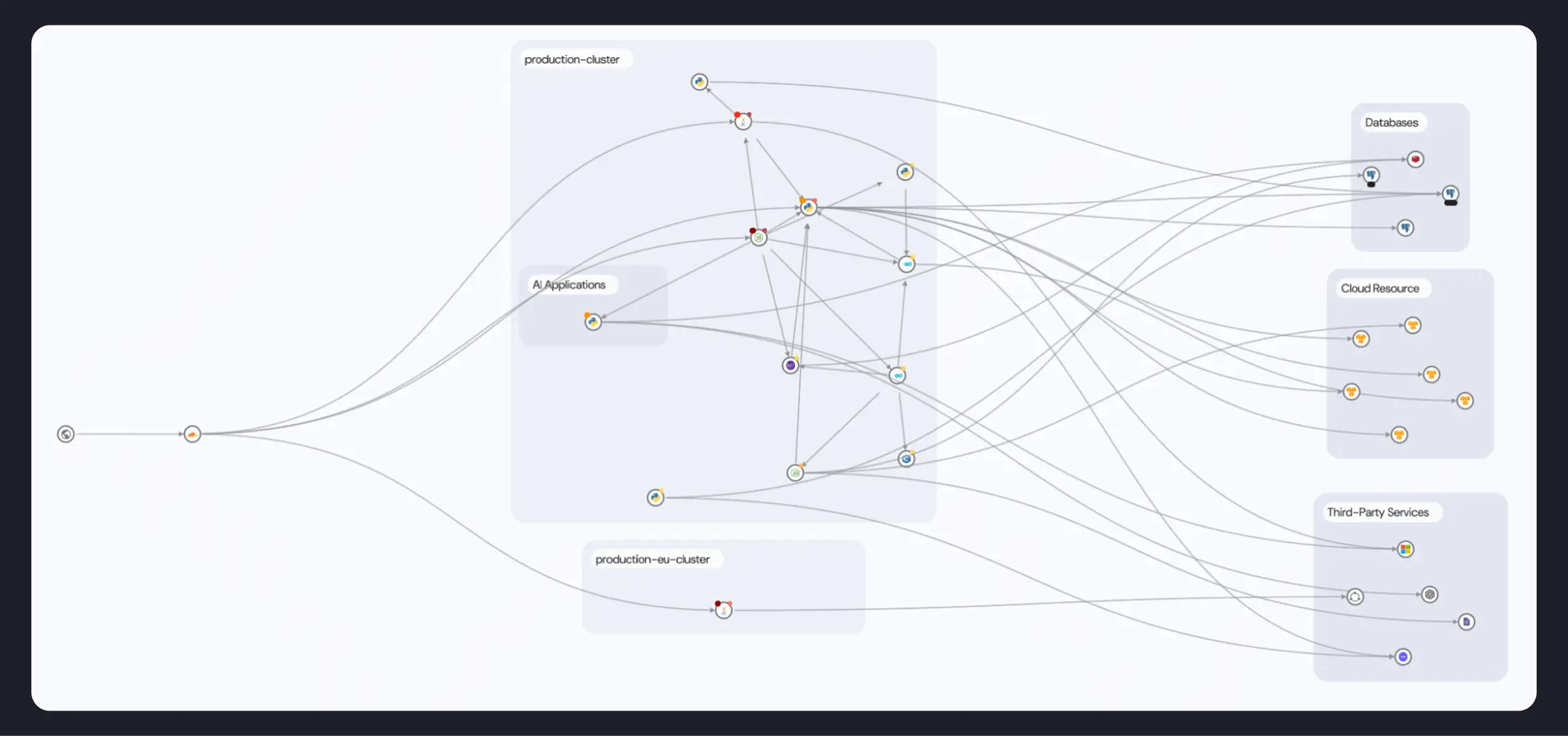
The first challenge is visibility: security starts with knowing what’s running. Miggo constructs a dynamic runtime application graph and continuously updated inventory of services, APIs, and third parties derived directly from Grafana Cloud telemetry.
By building an inventory and behavioral baseline of the application, MCP server, or agent, customers get an exposure map and Runtime BOM without interrupting developers' processes. Runtime data eliminates outdated architecture maps and confusion regarding what was planned vs. implemented. You get an up-to-date view of what’s actually running.
2. Evidence-based Prioritization
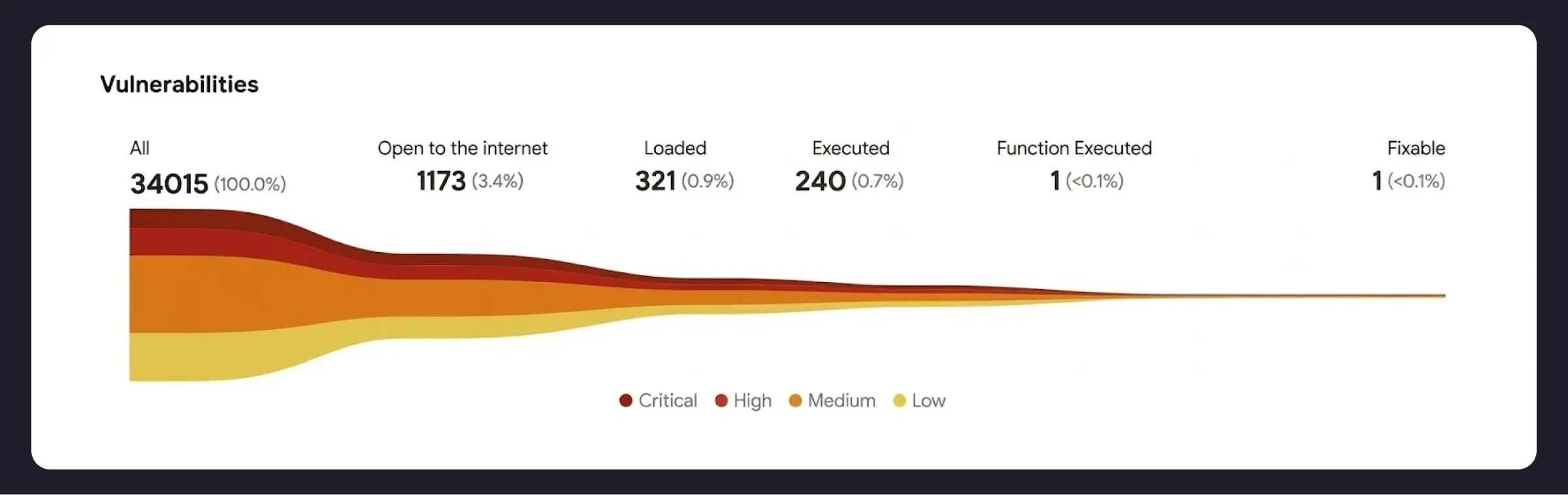
Once you establish what the application looks like, you can move beyond guessing to providing an opinion based on runtime truth. Miggo correlates vulnerabilities with Grafana Cloud Traces and Cloud Profiles to determine reachability and execution.
Traces bring environment context into vulnerabilities. Consider two services: an internet-facing API with access to PII in Postgres and Amazon S3 vs. an internal reporting job that runs every 24 hours and never touches user input. To your team, a high vulnerability on the former is more pressing than on the latter.
Profiles flesh out execution. Code can sit on disk and never run, yet still trigger scanner alerts. By analyzing profiles, Miggo determines whether a dependency is actually loaded — and whether a vulnerable function is ever called.
By validating static findings against runtime truth, organizations see a 60–90% reduction in critical vulnerability backlog noise. Because the evidence comes from traces and profiles that engineering and ops already work with, findings land with credibility and help bridge the divide between dev and security teams.
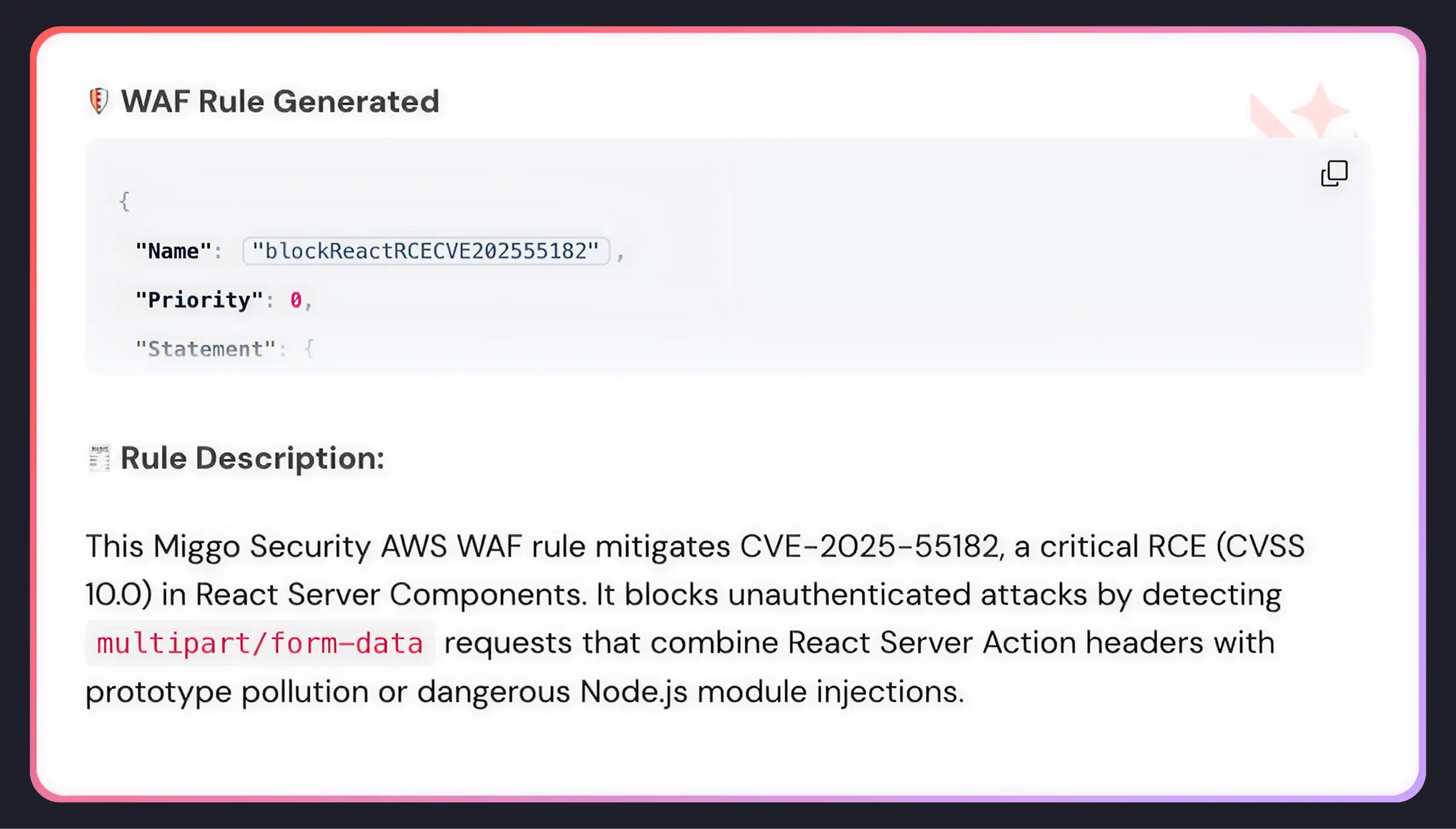
3. Immediate Mitigation via WAF Copilot
Runtime mitigation tools like pod termination are blunt instruments: they aren’t tailored to a specific vulnerability or a service’s runtime context, and carry the risk of disrupting production.
To reduce this friction, Miggo guides remediation with virtual patching via WAF Copilot. This provides a faster, less risky alternative to traditional patching, reducing the exposure window immediately while development teams implement permanent code fixes. WAF Copilot understands what a vulnerability does and how it can be exploited, generating precise rules that are robust against multiple exploitation patterns without blocking legitimate traffic.
To learn more about how Grafana Labs and Miggo Security are turning production telemetry into real security decisions, visit here.